Видео с ютуба Non-Autoregressive Vlm

What Are Vision Language Models? How AI Sees & Understands Images

Краткое объяснение больших языковых моделей
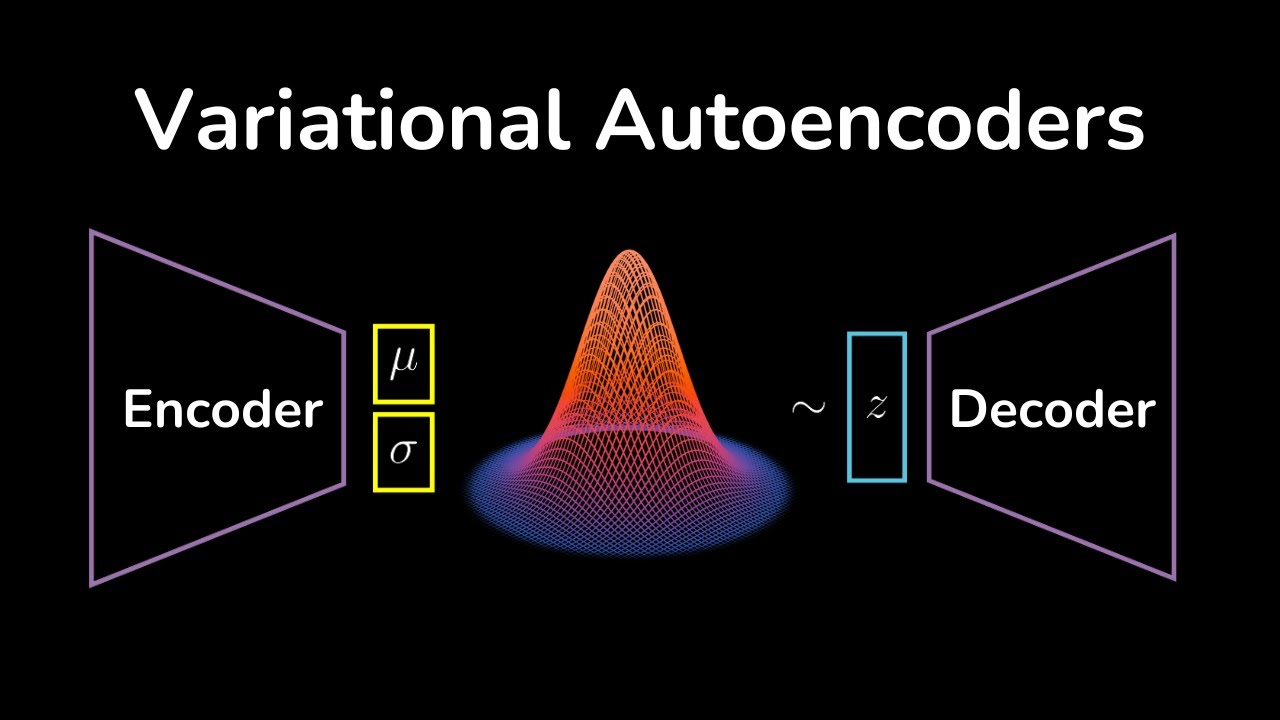
Вариационные автоэнкодеры | Генеративный ИИ-анимированный

Как Moondream создала VLM-платформу для сегментации языка (в соавторстве с Итаном Рейдом)

Autoregressive Models in 10 Minutes (Trick to Learn Gen AI) | Danial Rizvi

Fine-Tune Visual Language Models (VLMs) - HuggingFace, PyTorch, LoRA, Quantization, TRL
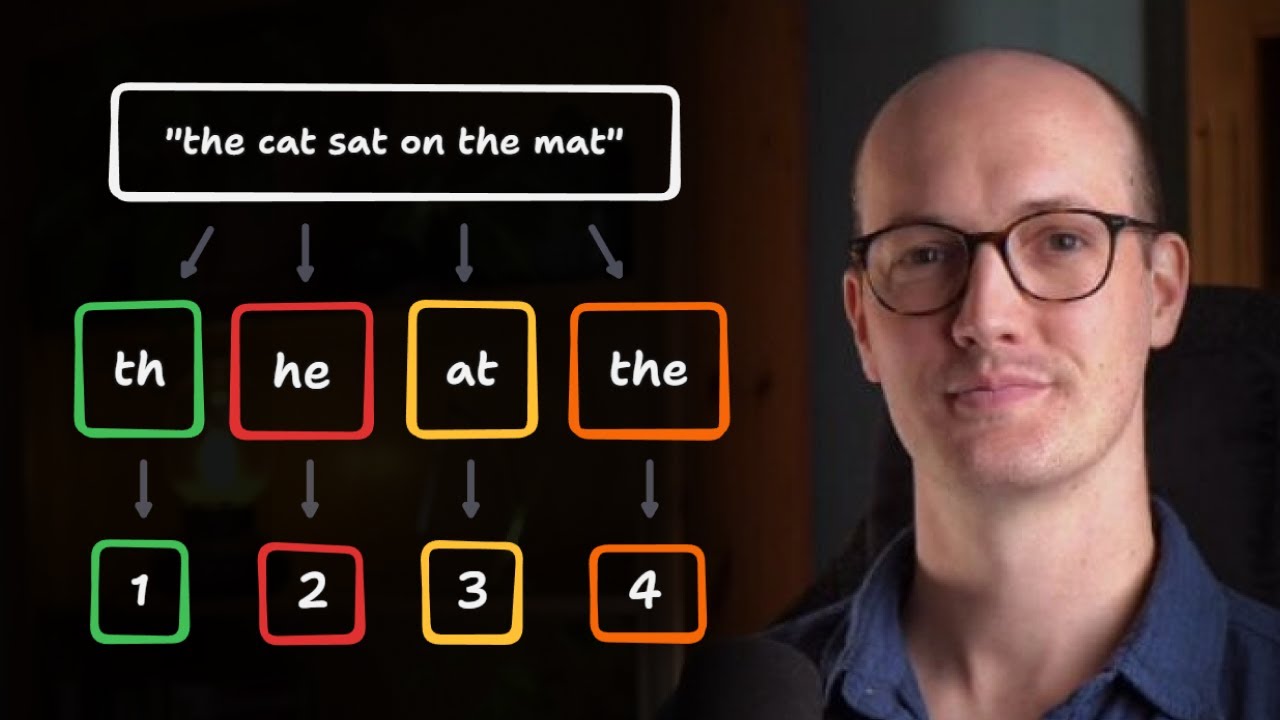
Большинство разработчиков не понимают, как работают токены LLM.

What If We Remove Tokenization In LLMs?

LLaVA-Critic-R1: Critic-to-Policy VLM via RL
![[VL-JEPA] Совместная архитектура прогнозирования встраивания для визуально-языковых моделей. V-JE...](https://imager.clipsaver.ru/D2il7SDF0Hc/max.jpg)
[VL-JEPA] Совместная архитектура прогнозирования встраивания для визуально-языковых моделей. V-JE...

The Future of AI That Thinks Before It Speaks | VL-JEPA Explained: How Meta Built Faster Vision

Мировые модели объяснены за 10 минут.

Визуализация внимания, сердце трансформера | Глава 6, Глубокое обучение
![[NVIDIA Cosmos] Почему именно модели реального мира? Следующая парадигма ИИ VLM и LLM для физичес...](https://imager.clipsaver.ru/KQFqS5p1U7U/max.jpg)
[NVIDIA Cosmos] Почему именно модели реального мира? Следующая парадигма ИИ VLM и LLM для физичес...

GenieReasoner: Precise VLA Reasoning and Action

Как на самом деле работает генерация изображений с помощью ИИ (существует всего 2 способа)

Галлюцинировать.УДАЛИТЬ = Мы нашли H-нейроны

Стэнфордский CS25: Объединенные трансформеры V6 I От языковых моделей к нативному мультимодальном...

Jehanzeb Mirza, GLOV: Guided Large Language Models as Implicit Optimizers for Vision Language Models
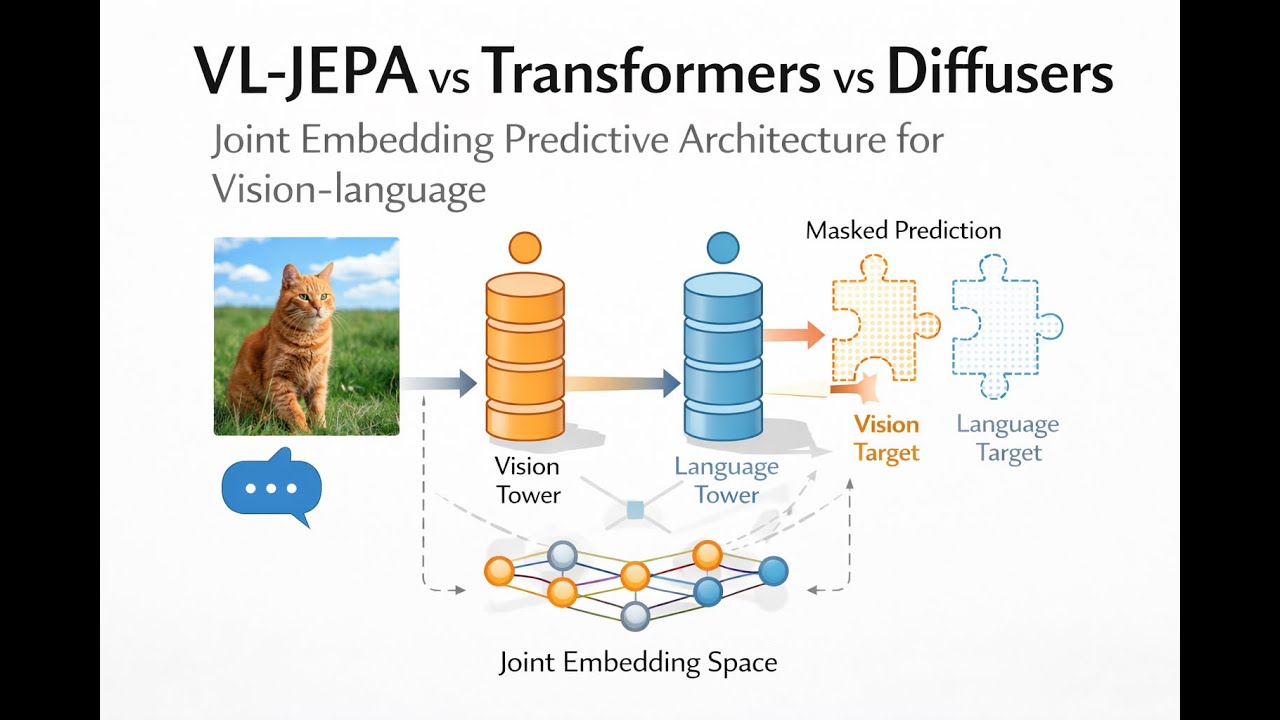
VL-JEPA против трансформеров против диффузоров. Совместная архитектура прогнозирования встраивани...